【読書メモ】Fundamentals of Software Architecture ~第三章 Modularity~
第三章は、Modularity(モジュラリティー)について。
MDN web docでModularityの定義をみると、以下のように説明されています。
システムのコンポーネントを分離して再結合できる程度を指しており、またソフトウェアパッケージを論理ユニットに分割することもあります。モジュラーシステムの利点は、部品を独立して考えることができることです。
この章では、モジュラリティーを理解するための三つの指標が提示されています。
cohesion(凝集度), coupling(結合度) それとconnascence(コナーセンス)です。
凝集度と結合度については、わかりやすい記事が既にあるので、ここでは飛ばします。
本記事では、残りのconnascenceについて詳しく触れていきます。
- connascenceとは
- Type of connascence
- 1. Connascence of Name (CoN)
- 2. Connascence of Type (CoT)
- 3. Connascence of Convention (CoC) / Connascence of Meaning (CoM)
- 4. Connascence of Algorithm (CoA)
- 5. Connascence of Position (CoP)
- 6. Connascence of Execution (CoE)
- 7. Connascence of Timing (CoT)
- 8. Connascence of Values (CoV)
- 9. Connascence of Identity (CoI)
- 3つの性質(Properties)
- 参考
- 英単語メモ
connascenceとは
凝集度と結合度は耳にすることも多いですが、connascenceは日本語だと情報がなかなか出てこないです。 connascenceは、Meilir Page-Jonesにより発明されたソフトウェア品質を測る指標だそうです。
coはtogather、
nascenceは'to be born' を意味するようです。
(ルネッサンス(Renaissance)は、re + nascence で復活の意味)
connascenceは複数のものが、同時に生まれるという意味になります。
では、ソフトウェア開発の文脈で、connascenceであるとはどういうことを指すのでしょうか。
connascenceの提唱者、Meilir Page-Jonesは、connascenceを以下のように定義しています。
two components are connascent if a change in one would require the other to be modified in order to maintain the overall correctness of the system.
二つのコンポーネントがconnascentである時、一方の変更が、システム全体の整合性を保つために、他方のコンポーネントの変更を要求する。
Type of connascence
次に、connascenceの種類について。全部で9種類存在するようです。
connascence.ioを元に、詳しく見ていきます。
1. Connascence of Name (CoN)
名前についての合意
function Aは、A()と呼び出す、という結合。
発見しやすく、リファクタもrenameで容易に可能。
2. Connascence of Type (CoT)
型についての合意 主に、静的型付け言語での話。例えば、以下のような例。
int age; age = 10.5 // TypeError
こちらも、静的型付け言語であれば発見しやすくリファクタも容易。
3. Connascence of Convention (CoC) / Connascence of Meaning (CoM)
意味についての合意
例えば、次のような関数はCoCによる結合を生み出す。
def get_user_role(username): user = database.get_user_object_for_username(username) if user.is_admin: return 2 elif user.is_manager: return 1 else: return 0
0, 1, 2のそれぞれの「意味」をget_user_roleを利用する側は知っている必要が出てしまう。 Enumとしてまとめることで、CoCの結合にすることができる。
4. Connascence of Algorithm (CoA)
アルゴリズムについての合意
複数のエンティティが同一のデータを扱う際にしばしば発生する。
例えば、次のようなコードは、エンコーディングがUTF-8である、という合意を元にしている。
def write_data_to_cache(data_string): with open('/path/to/cache', 'wb') as cache_file: cache_file.write(data_string.encode('utf8')) def read_data_from_cache(): with open('/path/to/cache', 'rb') as cache_file: return cache_file.read().decode('utf8')
また、サーバサイドとクライアントサイドの両方に実装される、 ハッシュアルゴリズムや、バリデーションロジックなどでも起きうる。
5. Connascence of Position (CoP)
位置についての合意
次のようなコードは、connascence of positionによって結合されている例だ。
def get_user_details(): # Returns a user's details as a list: # first_name, last_name, year_of_birth, is_admin return ["Thomas", "Richards", 1984, True] def launch_nukes(user): if user[3]: # actually launch the nukes else: raise PermissionDeniedError("User is not an administrator!") user = get_user_details() launch_nukes(user)
userというリストのうち、4つめの要素が権限を示すということを知らないといけない。 dictやエンティティにすることで、CoNの結合にすることができる。
6. Connascence of Execution (CoE)
実行順序への合意
例えば、リソースのロック/アンロックや、カプセル化されたステートマシンで起きうる。
以下のようなEmailSenderは、最後の2行が不正となる。
email = Email() email.setRecipient("foo@example.comp") email.setSender("me@mydomain.com") email.send() email.setSubject("Hello World")
このケースでは、実装箇所が近いため、発見は用意だが、 最後の2行が別スレッドで実行されるようなケース(high locality)では、発見が困難になる。
7. Connascence of Timing (CoT)
実行タイミングについての合意
例えば、複数スレッドで並行処理などで起きうる。
8. Connascence of Values (CoV)
値についての合意
例えば、以下のようなコードではArticleState.Draftが初期状態である、という合意が元にある。
class ArticleState(Enum): Draft = 1 Published = 2 class Article(object): def __init__(self, contents): self.contents = contents self.state = ArticleState.Draft def publish(self): # do whatever is required to publish the article. self.state = ArticleState.Published
テストコードでArticleの状態をチェックする際など、Articleクラスの初期状態を知っていなければいけなくなる。 しかし、そうなるとArticleクラスの初期状態がDraftではなくなった場合、テストケースは壊れることになる。
以下のように、初期状態を示す値を持つことで、その問題を回避できる。
class ArticleState(Enum): Draft = 1 Published = 2 InitialState = Draft class Article(object): def __init__(self, contents): self.contents = contents self.state = ArticleState.InitialState
例えば、初期状態がDraftから、Preproductionになった際は、以下のように変更すればよい。
class ArticleState(Enum): Preproduction = 1 Draft = 2 Published = 3 InitialState = Preproduction
9. Connascence of Identity (CoI)
同一エンティティについての合意
一般的な例としては、2つの別々のコンポーネントが、共通のデータ構造(例えば分散キュー)を共有・更新する時など。
3つの性質(Properties)
また、connascenceは3つの性質で見ることができるようです。
- degree:より強いconnascencesは、より発見しづらく、リファクタリングしづらい。
- locality:より多くのエンティティと、connascentであるエンティティは、問題の影響が大きくなる。
- strength:Connascentな要素は、コード上で近い位置に存在する方がよい
1. Strength
Connascenceには、強度が存在し、コードはConnascenceが弱くなる方にリファクタするべきとされている。
 CoNは、renameによって変更可能であるため結合が弱く、CoCはコード全体から変更を洗い出すことがより難しいため、結合は強くなる。
また、Static connascenceに比べ、Dynamic connascenceは実行時の挙動について知る必要があり、より強いconnascenceである。
CoNは、renameによって変更可能であるため結合が弱く、CoCはコード全体から変更を洗い出すことがより難しいため、結合は強くなる。
また、Static connascenceに比べ、Dynamic connascenceは実行時の挙動について知る必要があり、より強いconnascenceである。
2. locality
コンポーネント同士の近さ、を示す軸。 より強いconnascencesは、同一モジュール内などの近い関係では許容しやすく、 離れたコンポーネント間では、より弱いconnascencesであるべきである。
3. degree
connascenceが関与する影響度を示す軸。 結合が2つのコンポーネントに影響するのは、200のコンポーネントに影響するのかを見る。
参考
日本語での情報が少なく、あまり認知されていない(?)概念のように思われる。 以下、参考にしたリソースのメモ。
英単語メモ
■untangle (verb)
def: to separate pieces of string, hair, wire, etc. that have become twisted or have knots in them
def: to make something that is complicated or confusing easier to deal with or understand
■incarnation (noun)
def: a period of life in a particular form
def: a person who represents a particular quality, for example, in human form
【読書メモ】Fundamentals of Software Architecture ~第二章 Architectural thinking~
雲を見る時、気象学者の視点と、芸術家の視点では見ているものが異なるはず。
本書では、アーキテクトの視点でアーキテクチャを見ることを、Architectural thinking(アーキテクチャ的思考)と呼んでいます。
重要なポイントは、Architectural thinkingは、単にアーキテクチャについて考えることではないということ。
アーキテクチャ的思考には以下の4つの側面があると述べられています。
- アーキテクチャと設計の違いを理解し、アーキテクチャを機能させるためにチームとどのように協力していく方法を知る事。
- 幅広い技術的知識を持ちながらも、一定レベルの技術的な深さを維持し、他の人には見えない解決策や可能性を見出す事。
- 様々なソリューションと技術の間のトレードオフを理解し、分析し、調整する事。
- ビジネスドライバーの重要性を理解し、それがどのようにアーキテクトの懸念事項に反映されるかを理解する事。
<目次>
- Architecture Versus Design
- Technical Breadth
- Analyzing Trade-Offs
- Understanding Business Drivers
- Balancing Architecture and Hands-On Coding
- 英単語メモ
Architecture Versus Design
アーキテクトと開発者の役割の違い<Traditionalな分け方>
▼アーキテクトの範囲
- ビジネス要件を分析してアーキテクチャの特性(「能力」)を抽出・定義する
- 問題領域に適合するアーキテクチャのパターンやスタイルを選択する
- コンポーネント(システムの構成要素)を作成したりするコンポーネント(システムの構成要素)を作成したりする
▼開発者の範囲
この関係性の問題点は、アーキテクト -> 開発者 という一方方向な関係になっていること。
どうあるべきか、というのは以下の図のように示されています。

アーキテクトと開発者の垣根がないこと、そして共にイテレーションを回していくことがプロジェクト成功には重要とのこと。 つまり、どこからがアーキテクチャでどこからが設計か、という分け方ではないのだ、ということでしょう。
Technical Breadth
ここでは、アーキテクトが身に着けるべき技術的知識について書かれています。
まず、開発者とアーキテクトでは、求められる知識にどんな差があるのか。 それは、幅と深さである、と述べられてます。
書籍中では、以下のような図で説明されています。

技術的な深さは、「Stuff you know」(知っていること)を掘り下げていくこと。
技術的知識の幅とは、「Stuff you know you don't know」(知らないと知っていること)を増やしていくこと。
アーキテクチャ的な最適解を見つけるアーキテクトにとっては、
この技術的知識の幅をいかに広げていくか、が重要ということみたいです。
とはいえ技術的な深みや専門領域がなくてよい、という訳ではないのだと、
この後のセクションで触れられています。
Analyzing Trade-Offs
Architecture is the stuff you can’t Google.
Richards, Mark,Ford, Neal. Fundamentals of Software Architecture (Kindle の位置No.571-572). O'Reilly Media. Kindle 版.
この言葉の通り、アーキテクトが考えることは、トレードオフであり、
技術・ビジネス・組織の中で発生する要求や制約の中で、何を選択して何を選択しないか。
選択することによるメリットデメリット、選択しないことにより起きる条件制約。
置かれている状況の中でトレードオフを分析し、選択していくことがアーキテクトの考えで重要である、と述べられていました。
Understanding Business Drivers
アーキテクトの選択・決定はビジネス的要求とマッチしていることが重要、という話。 具体的にどう言った特性があり、どう考えればいいのかは、4〜6章の中で触れられているようです。
Balancing Architecture and Hands-On Coding
アーキテクトとしていかに、技術的深さやコーディングスキルを磨いていくか、という話。
三つの方法が紹介されています。
1. クリティカルパスや難しい箇所以外の開発に入る
この方法のいい所は、3つ
(1)アーキテクチャがプロダクトコードを書く機会を得られる
(2)開発チームがより難しい部分にフォーカスできる
(3)開発チームが感じている、プロセスや開発環境面での苦痛に気付ける
2. PoCの開発を担う
アーキテクトがPoCで開発を担うことで、
ドキュメント・構成管理・アーキテクチャなど、後の開発チームのガイドになるような土台を作れることがメリットの一つ。
アーキテクトにとっては、高品質で構造化された開発の腕を落とすことを防げるメリットがあるとのこと。
3. 技術的負債やバグ解決に関わる
コーディングスキルも磨きながら、コードベースやアーキテクチャの問題に気づくことができたり、
自動化やプロセス改善のきっかけにもなる。
また、コードレビューをすることで間接的にコーディングに関わることができ、
メンタリングやコーチングの機会も作ることができる。
第二章はここまで。
次回から、第三章に入ります。
英単語メモ
■quiver (verb)
def: to shake slightly; to make a slight movement
SYNONYM: tremble
■atrophy (noun)
def: (medical) the condition of losing fat, muscle, strength, etc. in a part of the body because it does not have enough blood
【読書メモ】Fundamentals of Software Architecture ~第一章 Introduction~ (2)
『Fundamentals of Software Architecture: An Engineering Approach』(以下、FoSA)の読書メモ、今回は第一章 Introductionの2回目です。
前回の記事はこちら
Intersection of Architecture and...
このセクションでは、ソフトウェアアーキテクチャと以下の4つについて書かれています。
- Engineering Practices
- Operations/DevOps
- Process
- Data
上から順に、見ていきましょう。
Engineering Practices
まず前提として、プロセスとプラクティスという考え方があるそうです。
- プロセスとは、どうやって「人」を動かすか(会議やチームビルディングなど)
- プラクティスとは、継続的に恩恵を生み出す仕組み(CI/CDなど)
アーキテクチャとしては、プラクティスにフォーカスを当てる事が重要とのこと。
例えば、マイクロサービスで必要な、自動プロビジョニング・自動テスト/デプロイなどをどう実現するかを決めること。
なぜプロセスとプラクティスを分けて考えるのか。
- (1) プラクティスはプロセスに依存せずに構築できるため。
- (2) 人間は「分からないとわかっていないこと」に対する推定が苦手なため。
「分からないとわかっていないこと」というフレーズは、2002年にラムズフェルド元米国防長官という人の発言として有名なようです。
詳しくはwikiを参照ください。
ジョハリの窓理論に由来するそうな。
プロジェクトの始まりは、「知らないと知っていること」を明らかにしていくこと。 例えば、開発者が予習しておくべき要素やドメイン知識など。
問題は、「知らないと知らなかったこと」にぶつかった時。 これについて、事前に考慮したプロセスを組むことは不可能で、 イテレーションを回して解決する他ないようです。
長くなったのでサマリとしては、
この二つがアーキテクトには求められるようです。
Operations/DevOps
かつては、運用はコスト削減のためアウトソースの対象、という背景があり、
アーキテクトは、運用は外部委託すると言う制約に対して防御的になるしかなかった。
その結果として、SPACE-BASED-ARCHITECTUREというアーキテクチャが生まれたそうです。
柔軟なスケールを実現するためにESB-driven SOAなども考案されたが、複雑であり、運用を考慮していなかった。
運用の関心ごとは運用でハンドルすべき
マイクロサービススタイルを築き上げた人たちは、そのことに気づいたそうです。
アーキテクチャーと運用をうまく連携させることで、
シンプルなアーキテクチャと、適切な運用を実現した。
不適切な姿は無駄な複雑性を産んでしまう、と本書で述べられてます。
Process
ソフトウェア開発プロセスと、アーキテクチャが独立しているというのはナンセンスと言う話。
本書では、イテレーションを回しながら進めていくプロセスの重要性が語られています。
イテレーションのいいところは、再構築性が高い事。 そもそも、アーキテクチャ自体の変更はあり得る。 最初はモノリスで初めても、あとあとマイクロサービス にするなど。 逆にウォーターフォールでマイクロサービスは現実的ではないよね、という話も出ていました。
Data
外部データはアーキテクチャにとって無視できないよって話。 詳しくはChapter 3で。
ソフトウェアアーキテクチャの原理原則
▼ソフトウェアアーキテクチャの第一原理:
Everything in software architecture is a trade-off.
ソフトウェアアーキテクチャのすべては、トレードオフにある。
▼ソフトウェアアーキテクチャの第二原理:
Why is more important than how.
「なぜ」は「どうやって」よりも重要である。
本書では、トレードオフを踏まえた決定の背景にある「なぜ」
に注目していく、というところで第一章が締まります。
今回はここまで。
次回から、第二章に入ります。
英単語メモ
■agnostic (noun)
def: a person who believes that it is not possible to know whether God exists or not
XX-agnositc で「〜に依存しない」
■nemesis (noun)
def: the person or thing that causes somebody to lose their power, position, etc. and that cannot be avoided
■infuse A into B | infuse B with A (verb)
def: to make somebody/something have a particular quality
■nomenclature (noun)
def: a system of naming things, especially in a branch of science
■delve into (phrasal verb)
def: to try hard to find out more information about something
【読書メモ】Fundamentals of Software Architecture ~第一章 Introduction~ (1)
『Fundamentals of Software Architecture: An Engineering Approach』(以下、FoSA)の読書メモ、今回は第一章 Introductionです。
そもそもソフトウェアアーキテクトとは何なのか。
本章の始まりは、「ソフトウェアアーキテクトは人気職種の一つだが、それになるための明確な道筋がないのはなぜか?」という問いから始まります。
対比として、ナース・プラクティショナーやファイナンス・マネージャも人気の職だが、キャリアパスが明確にあると例示されています。アーキテクトは学位だったり資格を取ればまずはokという訳ではないと言うことが言いたいのだと思います。
さて問いに戻ると、4つの理由が本章では提示されています。
- ソフトウェアアーキテクチャについての明確な定義がない
- 担う責任範囲が広い
- ソフトウェア開発のエコシステムが急激に進化している
- 時代依存が強い
ひとまず、アーキテクトという職に正解はないという事なのだと雑に理解。 このセクションで印象的だった箇所を引用します。
“Hey, I have a great idea for a revolutionary style of architecture, where each service runs on its own isolated machinery, with its own dedicated database (describing what we now know as microservices). So, that means I’ll need 50 licenses for Windows, another 30 application server licenses, and at least 50 database server licenses.”
(Kindle の位置No.159-161). O'Reilly Media. Kindle 版.
これは、2002年にマイクロサービスを実現しようとしたら、どうなるかという例です。 アーキテクチャ的な"正しさ"は、時代や状況(文脈)に依存するとはどういう事か、 なるほどこれはイメージしやすいと思いました。
Because everything changes, including foundations upon which we make decisions, architects should reexamine some core axioms that informed earlier writing about software architecture. (Kindle の位置No.153-154). O'Reilly Media. Kindle 版.
"正しさ"すらも変化する中で、良い姿を検討・検証することがアーキテクトの責務だと一旦理解して読み進めていきます。
ソフトウェアアーキテクチャを定義づける
アーキテクト がアーキテクチャを分析するとき、”何”を分析しているのか? 本セクションではこの問いを通じて、ソフトウェアアーキテクチャとは何か定義しています。
本書の定義によれば、ソフトウェアアーキテクチャは、
以下の3つを組み合わせた「システムの構造(Structure of the system)」
・アーキテクチャ特性(Architecture characteristics)
・アーキテクチャの決定(Architecture decisions)
・設計原則 (Design principles)
によって構成されるとされています。 以下、それぞれ詳細に触れていきます。
システムの構造
システムの構造は、アーキテクチャスタイルとも言われ、例えば microservices・layerd・microkernel といったもの。ただし、これだけではソフトウェアアーキテクチャ全体を言い表せないことに注意。 Architecture characteristics・Architecture decisions・Design principlesを理解して初めて、アーキテクチャを理解したと言える。
アーキテクチャ特性(Architecture characteristics)
一言で言うと、ソフトウェアを成功に導くための基準。 例えば、可用性・スケーラビリティ・信頼性など。
アーキテクチャの決定(Architecture decisions)
一言で言うと、システムがどう構築されるべきか定めるルール。 例えば、ビジネス層とサービス層のみがDBにアクセスできる、など。 アーキテクチャの決定は、システムに制約を設け、何が許容され許容されないかを開発者に指示するもの。
何らかの制約や条件によって、アーキテクチャの決定に則った実装ができないこともある。 そういった例外については、ARB(アーキテクチャ・レビュー・ボード)もしくはチーフアーキテクト により、 トレードオフの分析・検討を経て承認・却下されるべき。
※ARB: 組織横断的に構成される、アーキテクチャに関する意思決定機関。部門・企業を跨がり、経営層・パートナー企業・ステークホルダーから参加する。
設計原則 (Design principles)
一言で言うと、好ましい方法を示すためのガイドライン。 例えば、マイクロサービスのサービス間通信はパフォーマンスを高めるために非同期であること、という指針。 アーキテクチャの決定で、全ての条件・オプションをカバーするのは難しい。 代わりに、開発者が適切な選択をできるようにガイドラインを決めておくのが設計原則。
アーキテクトに求められる8つのこと
1. アーキテクチャの決定を作ること
アーキテクトとして、技術の選択ではなく、アーキテクチャの決定を作りチームを導くことが重要。 ただ、アーキテクチャ特性を維持するために、特定の技術を決定することもある。 アーキテクチャの決定については、19章で触れるよう。
2 継続的にアーキテクチャを分析すること
ビジネス・テクノロジーの変化に対して、過去に作られたアーキテクチャが現在もどれだけか、 構造に老朽化していないか分析すること。 また、テスト・リリースの環境についても考慮が必要。
3. 最新のトレンドから遅れをとらないこと
開発者が利用技術を追うことが必要なのに対し、アーキテクトは技術的・ビジネス的なトレンドを追うことが求められる。 アーキテクトの判断は、長期間影響し続け、一度決めたら容易に変更できないため、 間違った判断はよりクリティカルになる。
4. アーキテクチャの決定と設計原理が遵守されていることを確かめる
なんらかの理由によりアーキテクチャの決定に違反する実装が行われる可能性は0ではない。 例えば、パフォーマンスの問題から、プレゼンテーション層からDBアクセスしようとする開発者がいるかもしれない。 実装がアーキテクチャの決定に基づいているか確認することもアーキテクトの責務。
5. 多様なテクノロジー・フレームワーク・プラットフォーム・環境に触れること
深く知っているより、幅広く知識を持っていることが重要。 1のプロダクトのエキスパートであるよりも、10のプロダクトのpros/consを理解している方が アーキテクトにとって有益。
6. ビジネスドメインの知識を持つこと
アーキテクトがビジネスドメインについて理解していると、 ステークホルダーや経営陣とコミュニケーション取るのに有効に働く
7. 対人能力を持つこと
ジェラルド・ワインバーグが言う様に、"No Matter What They Tell You, It's a People Problem"、 つまり解決すべきは「人間が抱える問題」であり「技術的な問題解決」は手段にすぎない。 チームビルディング・ファシリテート力・リーダーシップなどのスキルを持つことはアーキテクトとして重要。
8. 企業の政治的風土を理解しナビゲートする
アーキテクトがどんなに素晴らしいアーキテクチャを設計しても、 それが現場で承認されなければ意味をなさない。 アーキテクトの決定は、コストや労力を伴う。 その時にプロジェクトマネージャ・ステークホルダー・開発者と交渉・説得することが求められる。 交渉力はアーキテクトに求められる能力の一つであり、23章で詳しく記されている。
今回はここまで。
英単語メモ
■elucidate (verb)
def: to make something clearer by explaining it more fully
synonym: explain
■hard-and-fast (adj)
def: definite and not to be changed, avoided, or ignored
■fool’s errand (noun)
def: a task that has no hope of being done successfully
■viable (adj)
def: that can be done; that will be successful
synonym: feasible
【読書メモ】Fundamentals of Software Architecture ~はじめに~
ソフトウェアアーキテクチャについて勉強してみたいと思い、『Fundamentals of Software Architecture: An Engineering Approach』(以下、FoSA)という本を買ってみました。
どうやら400ページくらいあるらしい。。。(しかも英語) このままだと、kindleアプリの中でデジタル文鎮になることでしょう。
と言う事で、少しづつまとめをアウトプットしながら読み進めようと決めました。 目次を見ると24章あるので、 各章につき1記事くらいのペースになる感じでしょうか。
初回の本記事では、FoSAを読み進める上での前提を確認していきます。
誰が書いたのか
FoSAの著者は、Mark RichardsとNeal Fordの2人です。 この二人が、どんなバックグラウンドを持ちFoSAを執筆したのか、 FoSA公式ページに掲載されているプロフィールを元に簡単にまとめます。
Mark Richards
マーク氏は、30年以上アーキテクトとして経験を積み、マイクロサービス・サービス指向アーキテクチャの構築・運用に20年以上携わる。 また、執筆・登壇・トレーナーとして活動し、developertoarchitect.comというウェブサイトの創設者でもある。 developertoarchitect.comでは、開発者からアーキテクトになるためのコンテンツが提供されている。
Neal Ford
ニール氏は、ThoughtWorks社でアーキテクト・ディレクター・ミームラングラー(ニール氏による造語)として勤務。 大規模エンタープライズアプリケーションの設計と構築に関してコンサルティングを行う。 アジャイル開発とアーキテクチャに関するエキスパートとして、国際的に知られている。
ThoughtWorks社といえば、Technology Radarを出している企業ですね。 和訳されているニール氏の著書として、『進化的アーキテクチャ』などがあります。
なぜ書いたのか
本の紹介文と序文を読むに、 この2点について問題意識があるようです。
1つ目については、第一章で詳しく取り上げられているので、次の記事で触れたいと思います。
2つ目について、序章に "Invalidating Axioms" という副題がついている点に注目しました。 まずは、Axiomの意味をOxford英英辞書で調べます。
a statement or proposition which is regarded as being established, accepted, or self-evidently true.
「自明で、確立された命題/定理」
Invalidating Axiomsは「確立していたものが、無効なものになっている」という意味になりそうです。
この序文の副題から、「かつて良いとされてきたアーキテクチャに対する認識を変えないといけない」という 著者らのメッセージがあると自分は理解しました。
また、タイトルの「Fundamentals」は、 土台とこれからのアーキテクトに向けたガイドを作る という著者らの目的意識が現れているのだと思います。
終わりに (この本を通じて、何が得られるのか)
公式ページによると、本書では以下の要素について記されているようです。
序文の中で、 This book won't make someone a software architecht overngint
と明言されていることから、入門書やHowTo本ではなさそうです。 ボリュームも内容もヘビーな感じがしますが、頑張って読んでいこうと思います。
実践 Vue Composition API
はじめに
Vue Advent Calendar 2019 9日目の記事です。 担当は@yktm31です。
Composition APIとは、Vue3から導入予定の新しいAPIです。 海外Vueカンファレンスでは、今や必ずトピックに上がるほど注目されています。
本記事では、そんなComposition APIでモリモリ開発する際の実装方針やTipsについて書いていきます。
扱う内容は、以下の6つです。
1. ディレクトリ構成 / 設計方針
2. Route
3. 状態管理
4. ComposableなRepositoryFactory
5. ComposableなPolling
6. テスト
今回、上記の要素を含んだ簡易なサンプルを作成しましたので、宜しければ参考にしてください。 Github
<目次>
Main Contents
1. ディレクトリ構成 / 設計方針
まずは、ディレクトリ構成について。 基本はContainer/Presentationalをベースにするとスッキリまとめられそうです。 下記がディレクトリ構成例になります。configファイル等は省略しています。
src ├-- views ① ページに相当する ├-- presentationals ② 見た目/デザインに責務を持つ ボタンなど ├-- containers ③ ユーザのアクションに対して、ロジックを実行しレスポンスする責務を持つ ├-- repositories ④ REST APIなど、外部リソースへのアクセスに責務を持つ ├-- compositions ⑤ Composition Function ├-- store ├-- router ├-- App.vue ├-- main.ts ├-- shims-tsx.d.ts └-- shims-vue.d.ts
①〜③ コンポーネント分割方針
Composition APIで書く = コードが構造的になる ではありません。RFCでは、こう表現されています。
More Flexibility Requires More Discipline
Composition APIの恩恵で、より柔軟にロジックを組めるようになります。 しかし、だからこそちゃんと設計しないと、ロジックが散乱しカオスな状況に陥りかねません。
そこで、プロジェクトで通底する構造を作っていく必要があります。
本記事では、Container/Presentational/view の3つを基本としたコンポーネント分割をしていきます。
それぞれの責務は以下になります。
- container: ロジックを実行し、状態を操作する。
- presentational: containerを親に持ち、Propsで受け取ったデータに基づきHTMLを返す。
- view: containerを組み合わせてページを作る
ベースになっているのは、Container/Presentationalという、redeux開発者のDan Abramov氏が提唱した考えです。 こちらの記事が元記事です。
実はこの考え、2013年に出されたもので少し古いものです。 元記事の中でも、今ではHookがあるので、この考えである必要はないと言っています。 しかし、この考えに基づき、コンポーネントの責務を明確にすることは有用だと考え、採用しています。 全体を把握しやすく変更・拡張が容易な構造を作るため、 シンプルなルール・わかりやすい関係性を意識しています。
④ Repository
こちらは、RepositoryFactoryという考えに基づき、REST APIなど外部リソースへのアクセスを隠蔽します。 この考え方は、Vue evangelistのJorge氏が2018年にmediumで出した記事(日本語訳)で提唱されています。
そこで、この考えをベースに、Composition APIライクなRepositoryFactoryを実装します。 詳細は、この先で触れます。
⑤ Composition Function
コンポーネントから抽出したComposition Functionを置きます。 さてここで、「Composition Functionに切り出す出さないの判断基準は?」という疑問が湧いてくるかと思います。
自分としては
ベースとしているのは
- SFCの考えを踏襲する
- ロジックの関心ごとに分ける という二つの観点です。
本記事では、Polling処理をComposition Functionとして切り出す例を紹介します。 詳細は後述します。
2. Router
ここまで、考え方的な部分に触れてきました。 ここからは、実装よりの話になっていきます。
まずは、Routerについてです。早速実装を見ます。
<script lang="ts">
import { createComponent, SetupContext, ref, onMounted } from "@vue/composition-api";
import Button from "@/presentationals/Button.vue";
export default createComponent({
components: {
Button
},
setup(_, context: SetupContext) {
// ページ遷移を行う。
function moveToNextPage() {
context.root.$router.push({ name: "home" });
}
return {
moveToNextPage
};
}
});
</script>
Vue2で、Vueインスタンス内部からrouterを呼ぶ際には、 this.$routerを使っていました。
this.$router.push({ name: 'user', params: { userId: 123 }})
Vue3では、thisは廃止され、代わりにsetup()の第二引数、SetupContextからアクセスできます。
3. 状態管理
Composition APIを使った状態管理については、これまでいくつか詳しい記事が出ています。
- Vue Composition API を使ったストアパターンと TypeScript の組み合わせはどのくらいスケールするか?
- 【Composition API】StoreパターンでVuexを使わずに状態管理をする
- Vue Composition APIのコラムっぽいもの集#Vuexはいらなくなる?
加えて、2020年2月に行われる、vuejs.amsterdamで、 vueコアチームの方が、「Vuexいらないかも?」というテーマで登壇されるようです。
"You might not need VueX", according to #vue Core Team Member @N_Tepluhina🤩.
— vuejs.amsterdam (@vuejsamsterdam) December 13, 2019
Natalia is a Senior Frontend Engineer @gitlab and a🗜️@GoogleDevExpert.
See you in Feb 2020 @N_Tepluhina 😃 pic.twitter.com/5jpUOHqxDo
<2020/3/16追記> この発表資料はこちらです。 https://speakerdeck.com/ntepluhina/you-might-not-need-vuex
個人的には、いまいまグローバルに状態管理したいときはVuexを使っています。 理由としては、Composition APIを使った実装だと、DIしたりと実装が重くなると考えているからです。 Vue3/Composition APIでの状態管理、 Vuexが追従するのか、新しいライブラリが出てくるのか、要チェックなところです。
<2020/3/16追記> Vuex4にて、Vue3への追従が行われることが発表されました。 Vuex4 2020/3/16現在、TypeScriptのサポートは無いようですが、 READMDを見る限り、TypeScriptサポートに向けて開発が進んでいるようです。
Vuex 4.0 branch has opened, and 4.0.0-alpha.1 is released! 🌟 This is the Vue 3 compatible version of Vuex. It has the exact same API with Vuex 3, except for the installation process. Please provide us feedback if you find anything 🙌https://t.co/qt4g43uH93
— Kia King Ishii (@KiaKing85) March 15, 2020
4. ComposableなRepositoryFactory
上で書いた通り、RepositoryFactoryという考えに基づき、REST APIなど外部リソースへのアクセスを隠蔽します。 このRepositoryFactoryを、Composition APIを利用して、実装する例を紹介します。
Composition APIを使って実装するメリットとしては、コンポーネントのなかで、asyncを使ったRepository呼び出しが必要がない点です。 レスポンスやローディング中かどうかなど、状態も含めてComposition Functionの中に押し込められます。
これにより、よりシンプルにAPI呼び出しがかけるようになります。
以下、実装例を見ていきます。
バックエンドとして、flaskで簡単なAPIサーバを立てています。
import logging import time from datetime import datetime from flask import Flask, jsonify, request from flask_cors import CORS app = Flask(__name__) CORS(app) @app.route('/api/sample/get', methods=['GET']) def get(): now = datetime.now().isoformat() return jsonify({'time': now}) @app.route('/api/sample/get2', methods=['GET']) def get2(): msg = request.args.get('msg') return jsonify({'msg': msg}) if __name__ == '__main__': app.run(host='0.0.0.0', port=5000, debug=True)
まずはaxiosをラップしてRepositoryを作ります。
import axios, { AxiosInstance } from "axios"; const baseDomain = "http://localhost:5000"; const baseURL = `${baseDomain}/api`; let Repository: AxiosInstance = axios.create({ baseURL: baseURL }); export default Repository;
次に、ファクトリを作ります。
import useSampleRepository from "./SampleRepository" import { Ref } from '@vue/composition-api'; interface Repositories { [key: string]: Function; } const repositories = { sample: useSampleRepository } as Repositories; export const RepositoryFactory = { create: (name: string): any => { return repositories[name]; } };
こちらが、Composition APIを使ったRepositoryになります。
import Repository from "./Repository"; import { ref } from "@vue/composition-api"; const resource = "/sample"; export default function useSampleRepository() { let response1 = ref(); async function getSample() { const { data } = await Repository.get(`${resource}/get`); // レスポンスをrefで包んだ変数に格納。 response1.value = data; return data; } let response2 = ref(); async function getSample2(msg: string) { const { data } = await Repository.get(`${resource}/get2`, { params: { msg: msg } }); response2.value = data; return data; } return { getSample, getSample2, response1, response2 }; }
コンポーネントでの使用例はこちらです。
<script lang="ts">
import { createComponent, SetupContext, ref } from "@vue/composition-api";
import Button from "@/presentationals/Button.vue";
import TextField from "@/presentationals/TextField.vue";
import { RepositoryFactory } from "@/repositories/RepositoryFactory";
export default createComponent({
components: { Button, TextField },
setup() {
// Composition FunctionとしてのAPI呼び出しメソッド、およびそれらのレスポンスを受け取る変数を準備する。
const { getSample, getSample2, response1, response2 } = RepositoryFactory.create("sample");
// templete内で参照・呼び出しできるように、returnする。
return { getSample, getSample2, response1, response2, value };
}
});
</script>
5. Polling
Pollingについても、Composition APIを使うと、簡単に実装できます。
利点としては、コンポーネントでポーリング自体のロジックを組む必要がなくなることです。 また、ポーリングに関する状態もComposition Functionが持っているので、コンポーネントから制御することができます。
例えば、ページを離れる際にポーリングを終了したい時は以下のようにできます。
<script lang="ts">
// ・・・略・・・
const { polling, pollingDisable } = usePolling();
// コンポーネントマウント前にポーリングを開始する。
onBeforeMount(() => {
polling(someFunction);
});
// コンポーネント切り替え時に、ポーリングを停止させる。
onBeforeUnmount(() => {
pollingDisable.value = true;
});
// ・・・略・・・
</script>
実際の実装はこちらになります。
import { ref } from "@vue/composition-api"; // delayミリ秒待機する。任意の第二引数を結果として返す。 async function sleep(delay: number, result?: any) { return new Promise(resolve => { setTimeout(() => resolve(result), delay); }); } export default function usePolling() { // ポーリング制御用のフラグ let pollingDisable = ref<Boolean>(false); // ポーリングで実行する関数と、ポーリング間隔時間を引数として受け取る。 async function polling( fn: Function, intervalTimeMsec: number = 3000 ) { // 無限ループを回し、ポーリングする。 // pollingDisableの値がtrueになれば、ポーリングを終了する。 for (;;) { await sleep(intervalTimeMsec).then(status => { fn(); }); if (pollingDisable.value) { break; } } } return { polling, pollingDisable }; }
6. テスト
テストについては、以下の2つの記事が参考になります。
とはいえ、丸投げにするわけには行かないので、上で取り上げたRepositoryFactoryのユニットテストを書いていきます。
import { createLocalVue, mount, shallowMount } from "@vue/test-utils"; import VueCompositionApi from "@vue/composition-api"; import useSampleRepository from "@/repositories/SampleRepository"; import Repository from "@/repositories/Repository" // composition APIを有効にする。 const localVue = createLocalVue(); localVue.use(VueCompositionApi); // Repositoryをモック化する。 const mockedRepository = Repository as jest.Mocked<typeof Repository> jest.mock('../../../src/repositories/Repository'); beforeEach(() => { mockedRepository.get.mockReset(); }) describe("SampleRepository", () => { it("getSampleTest", () => { mockedRepository.get.mockResolvedValue({data: "test"}); const { getSample, response1 } = useSampleRepository(); return getSample().then((res: string) => { expect(res).toEqual("test"); expect(response1.value).toEqual("test"); }); }); it("getSampleTest2", () => { mockedRepository.get.mockResolvedValueOnce({data: "no"}); const { getSample2, response2 } = useSampleRepository(); return getSample2("-").then((res: string) => { expect(res).toEqual("no"); expect(response2.value).toEqual("no"); }); }); });
ポイントとしては、
- Repositoryをモック化する。
- レスポンスを受け取るrefで包んんだ変数の値をチェックする の2点です。
最後に
最後まで読んでいただきありがとうございます。 長くなりましたが、これまでComposition APIを使い、試行錯誤して考えてきたことを紹介させていただきました。
尚、私の個人的な経験ベースでの話が多くなっています。 もし、もっといいやり方がある・それは良くない、という点があればコメントいただければ嬉しいです。
また、開発規模の大小によって適切な構成があると思いますので、ひとつの参考になればと思います。 一応、本記事では、小〜中規模くらい(ページ数が3〜7程度)を想定しています。
Composition APIはまだ成熟しきっていないと思います。 しかし、Vueにとって新しいパラダイムとなるのは確実だと思っています。
何より、Compoosition APIめちゃくちゃ楽しいのです! どんどん普及して、色々なプラクティスが出てくるといいなと思い、本記事を執筆しました。
それでは、楽しいVue Lifeを!
Azureでサーバレス 、監視はどうする? 試して分かった、7つのこと
はじめに
Azure Advent Calendar 2019 1日目の記事です。 担当は@yktm31です。
本記事では、Azure上でサーバレスシステムを分散トレーシングで監視しようと試みた際に、 できたこと・難しかったことをまとめていきます。
AzureにはApplication Insightsという、Webアプリケーションを監視するためのサービスがあります。 パフォーマンスや例外、セッション数などを監視することができます。(公式)
今回、Application Insightsを利用し、リソース間関係・ボトルネックの可視化を目指しました。 下記の記事でやっている事をAzureでもやってみるというイメージです。 AWS X-RayでLambdaとAWSリソースをトレースする(Python)
システム構成
監視対象とするシステムは、Azure Functionsをメインに使った、サーバレスなLine Botです。 使用言語はpythonを利用しました。
Lineで写真を送ると、物体に矩形がついた写真が返ってくるというものです。 利用した技術要素としては、以下の様な感じです。
- Line Messaging API
- YOLOv3
- Flask
- Azure周り
Functinos / Storage / Container Instance / Container Registry / Service Bus / Application Insights - OpenCensus(※後述)
構成は以下の通りです。
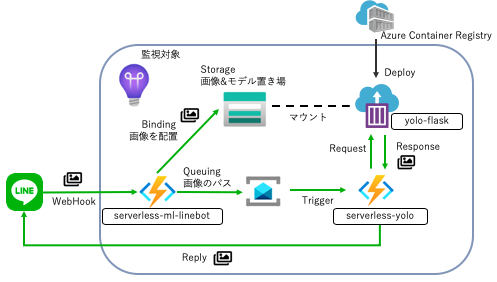
可視化したい箇所は。図中の緑の線です。 このシステムをApplication Insightsを利用して、監視してみました。
なお。今回詳しい実装については触れませんので、ご容赦ください。
気が向いたら、別の記事で書くかもしれません。
また以下についても説明を割愛させていただきます。
・分散トレーシングの詳細な挙動
・Azure Functionをはじめとする、Azure各リソースの作成・デプロイ方法
・Line Messaging APIの実装について
わかった事
1. そもそも、Pythonはプレビュー段階で、サポートされていない部分が多い
タイトルの通りですね。公式のドキュメント読んでいると、C#や.Net、JavaScriptに比べ、Pythonはサポートしていないという機能がいくつかありました。 Python アプリケーション用に Azure Monitor をセットアップする (プレビュー)
この先に触れていくことも、Pythonだと難しいが、他の言語ならできるということはあります。 最初の言語選択として、どの程度親和性が高いかは最初にみておいた方が良さそうです。
2. Application Insightsの依存関係は、Operation Idで紐づけられる
分散トレーシングの基本概念として、SpanとTraceというものがあります。 Spanとは、1処理・1コンポーネントという単位です。 k8sで言えば1Pod、FaaSで言えば1関数という単位になるかと思います。
Traceとは、関連するSpanをつなぎ合わせた、一連のSpanの集合です。 Spanについているtrace_idとspan_idを伝播させていくことで、各処理のトレーシングを実現します。 この辺のことについては、下記の資料が分かりやすかったです。 クラウドネイティブ時代の分散トレーシング - Distributed Tracing in a Cloud Native Age
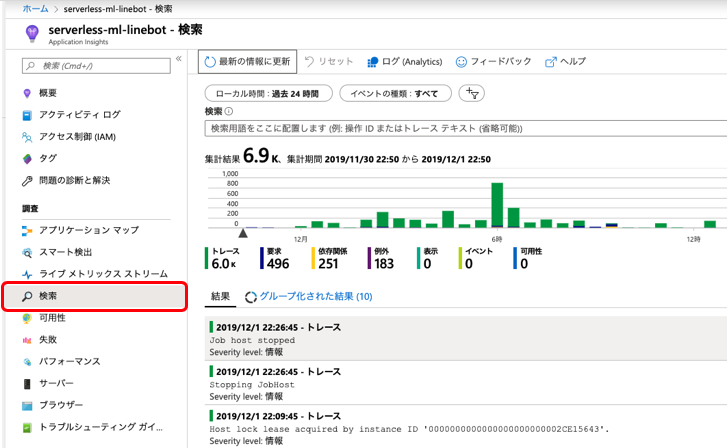
Application InsightsでのOperation Idは、Trace IDに当たります。 Azureでは、下記のドキュメントに各用語について解説されています。 Application Insights Telemetry のデータ モデル
というわけで、同じOperation Idを持つリクエストやログは一連の処理として紐付けられます。 Application Insights上で確認してみます。 Application Insightsのリソース画面に移動し、「検索」を押します。
トレースを選び、クリックすると以下のように表示されます。

タイムラインを表示すると、こうなります。 右上の操作IDが、OperaitionIDになります。
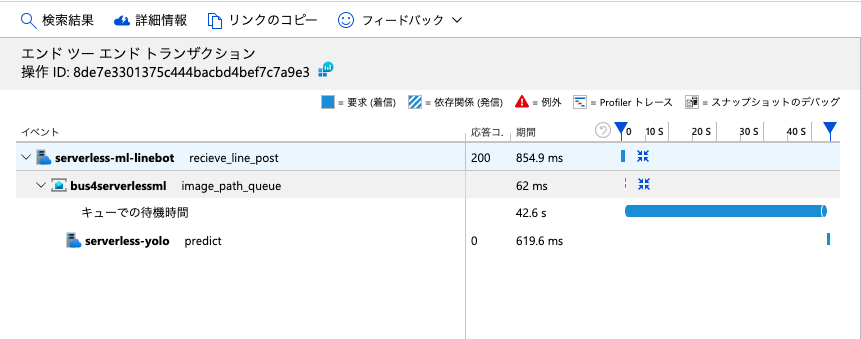
呼び出しの親子関係がわかり、それぞれの実行時間を可視化することができました。
3. Azure Functionsは関数毎ではなく、リソース毎にマップされる
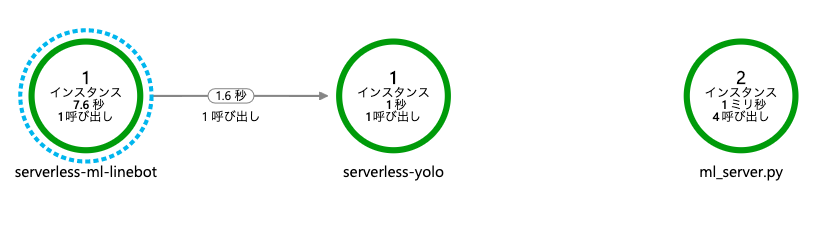
これが一つ目の罠でした。 まず前提として、Azure Functionsは、一つのリソースに複数の関数を作成することができます。 しかし、一つのリソースにある関数は、Application Map上では一つのノードとして表示されてしまう様です。
次の記事は2018年のものですが、1関数ごとにリソースを作成し、関数をマッピングさせています。 Azure Functions 2.0 – Real World Use Case for Serverless Architecture
今回、serverless-ml-linebotと、serverless-yoloという二つの関数を、別のリソースとして作成しました。 確かにそれぞれAplication Mapに表示できました。 ただ、2つ3つ程度ならばまだしも、大規模になると大変そうです。
今後のアップデートで対応されて欲しい部分の一つですね。
4. Azure FunctionsのBindingsを使うと、自動で依存関係を収集してくれる
Azure Functionsで複数の関数を一連の流れとしてまとめる場合、どうなるのか。 Bindingsを利用すれば、自動で依存関係を収集してくれます。 例えば。関数AがServiceBusにキューを詰めて、関数Bがキューをトリガーにして発火するというケースであれば、 同じOperation IDを自動で付与してくれます。
今回、serverless-ml-linebotが発火すると、ServiceBusにキューを詰め込み、serverless-yoloがそれをトリガーに発火します。 この一連の処理に同一のOperation IDが付与され、Application Insightsが自動で依存関係を収集してくれます。

Applicatoin Mapでは、この様に表示されます。
5. Azure SDK for Pythonでは、依存関係の収集に対応していない?
Azure Functionsから、StorageCosmosDBにデータを入出力する別の方法として、 Azure SDK for Pythonがあります。
ただ、Azure SDK for Pythonを利用した方法だと、トレースはしてくれるものの、 依存関係を作っては入れない様です。
したがって、タイムラインには親子関係として表示されない上に、 Application Mapにもマップできないことになります。
なぜできないのかを解明するために、Azure-SDK-For-Pythonのソースコードを読んでみると、 distributed_traceというデコレータが実装されていることが分かりました。GitHub
原因の解明とはいきませんでしたが、今後対応される見込みはたかそうです(?)
6. Application Insights SDK for Pythonは、OpenCensusに統合される
Application InsightsのPython向けSDKは、今はOpencensusに統合されているようです。 Microsoft joins the OpenCensus project
OpenCensusとは?
OpenCensusは、アプリケーションにObservabilityを提供するライブラリで、 以下の3つの機能を持っています 1. リクエストのトレースと、時系列メトリクスを収集する 2. 収集した結果を可視化する 3. 収集した結果を別の分析用アプリケーションに送出する。
また、Azureとして分散トレースの標準をW3Cが出している、Trace Contextに移行している最中だそうです。 これにより、旧来Application Insightsが、分散トレースのために使っていたHTTP Headerなどは置き換わって行くことになるそうです。
今回は、serverless-yoloから、flask-yoloに対するリクエストを投げる部分を、OpenCensusを利用して監視しました。
APIを叩く側の実装は、リクエストヘッダに traceparent という値を追加するだけです。 traceparentの詳細な仕様は、こちらのドキュメント(日本語訳)にあります。
値としては、 00-0af7651916cd43dd8448eb211c80319c-00f067aa0ba902b7-01 というものになります。 形式は、 00-{trace_id}-{span_id}-{flag} です。
headers = {'traceparent': traceparent}
requests.get(url='https://yolo-flask/predict', headers=headers)
リクエストを受ける側のFlaskは、opencensus-ext-flaskというモジュールを利用します。 実装はほぼサンプル通りです。
import logging import json from flask import Flask, jsonify, request from opencensus.ext.azure.trace_exporter import AzureExporter from opencensus.ext.flask.flask_middleware import FlaskMiddleware from opencensus.trace.samplers import ProbabilitySampler from opencensus.trace.tracer import Tracer app = Flask(__name__) # Application Insightsの接続文字列 APPLICATION_INSIGHTS_CONNECTION_STRING = 'InstrumentationKey=XXXXXXX' exporter = AzureExporter(connection_string=APPLICATION_INSIGHTS_CONNECTION_STRING) sampler = ProbabilitySampler(rate=1.0) middleware = FlaskMiddleware(app, exporter=exporter, sampler=sampler) tracer = Tracer( exporter=AzureExporter(connection_string=APPLICATION_INSIGHTS_CONNECTION_STRING), sampler=ProbabilitySampler(1.0) ) @app.route('/yolo-flask/predict', methods=['GET']) def post(): msg = 'ok' return jsonify({'res': msg}) if __name__ == '__main__': app.run(host='0.0.0.0', port=5000)
7. Pythonでは、Azure FunctionsのOperation Idを取得できない
これはかなり詰まったところです。 2番でも触れた様に、アプリケーション間の親子関係を作るためには、trace_idと、span_idというものが必要になります。
Azure Functionsから、別のAPIを叩きたいようなケースの場合、 Operation Idを取得できないという問題がありました。
これはつまり、trace_idで関連付けできないことを意味します。 今回のシステムで言えば、serverless-yoloから、flask-yoloのAPIを叩きたいようなケースです。 6番のケースですね。
半ば強引に実装し、trace_idで関連付けはできたものの、、うまく親子関係にすることができません。

Application Mapも、依存関係をマッピングできていません。
今後のアップデートで、うまく扱えるようになってくれると嬉しい部分ですね。
最後に
AWSならX-Ray GCPならStackdriverのように、各クラウドごとに分散トレーシングの事例も情報も多かったのですが、 Azureについては少なかったように感じていました。実際にやってみて、思う様にいかないケースもあり、大変でした。
今後、アップデートを追いかけたりして、Azureでのマイクロサービス・分散トレーシングを頑張っていきたいです!